实现chatGPT,你需要知道这些数据集和模型
发布时间:2023-05-25
根据提示生成数据
该项目涵盖了2000多种文本提示,170多种英文数据集
GitHub:https://github.com/bigscience-workshop/promptsource
论文:【多任务提示训练实现零镜头任务化】
https://arxiv.org/abs/2110.08207
使用模板生成的数据集:
1.https://huggingface.co/datasets/bigscience/P3
2.https://huggingface.co/datasets/bigscience/xP3(多语言数据和使用英文提示)3.https://huggingface.co/datasets/bigscience/xP3mt(多语言数据和机器翻译过的提示)
以此训练的zero-shot模型
T5架构(编码器-解码器),称为 T0 系列(MT0 用于多语言,基于MT5微调,MT5为T5多语言版本)
GPT架构(只有解码器),称为 BloomZ 系列(基于bloom微调)
huggingface:
【T0】:https://huggingface.co/bigscience/T0pp
【MT0】:https://huggingface.co/bigscience/mt0-large
【BloomZ】:https://huggingface.co/bigscience/bloomz
T0的GitHub 存储库:https://github.com/bigscience-workshop/t-zero
BloomZ 和 MT0 的 GitHub 存储库:https://github.com/bigscience-workshop/xmtf
自然语言指令
● GitHub:https://github.com/allenai/natural-instructions
● 论文:【超自然指令:通过1600+ NLP任务的声明性指令进行泛化】 https://arxiv.org/abs/2204.07705
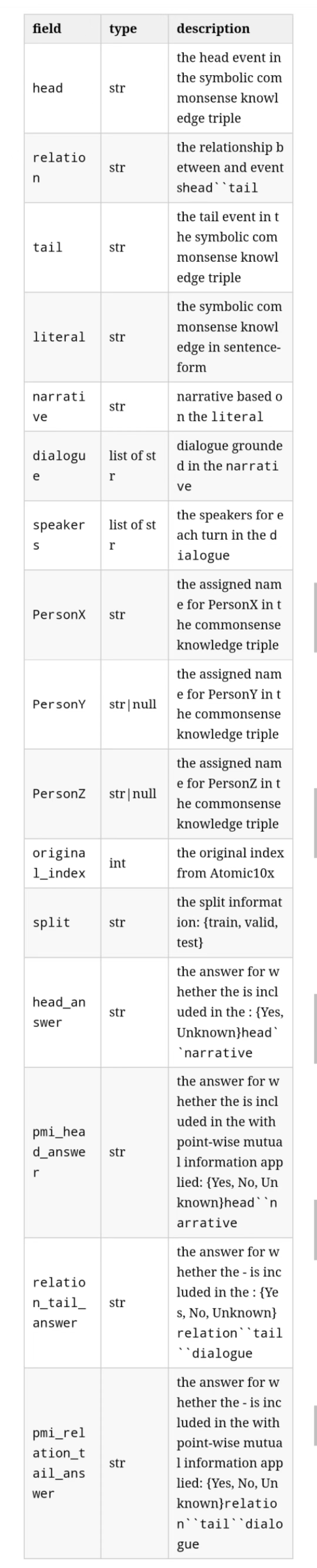
● 数据集就在代码库里,json格式。
● 模型:
1.mT5 架构(编码器-解码器、多语言预训练)
2.few-shot:https://huggingface.co/allenai/tk-instruct-3b-def-pos
3.zero-shot:https://huggingface.co/allenai/tk-instruct-3b-def和InstructGPT训练的数据集比, sup-matinst包含更多任务的数据集
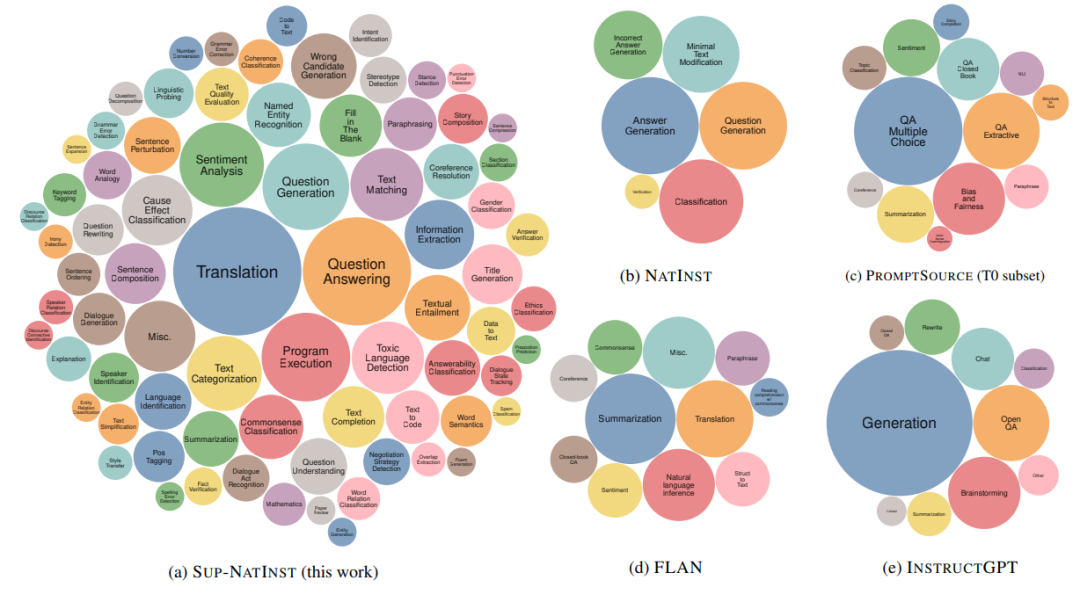
image-20230225150928382

image-20230225145914595
融合特征
●Facebook在Blenderbot项目中的使用的对话数据,融合knowledge、empathy、persona三种特征
●数据集:https://huggingface.co/datasets/blended_skill_talk
●模型:https://huggingface.co/facebook/blenderbot_small-90M
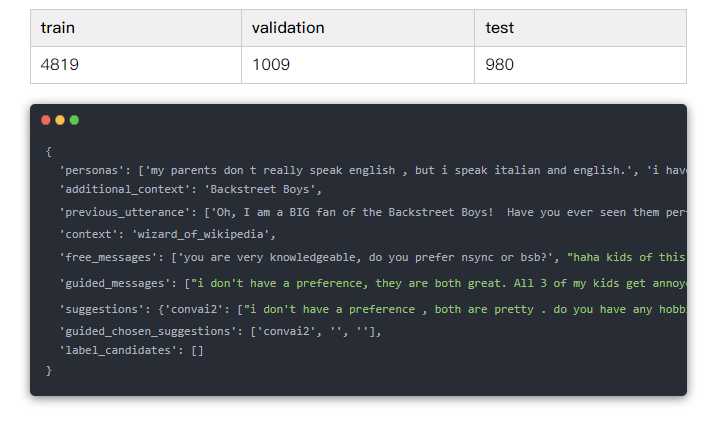
SOTA
包含38.5万个对话的高质量数据
想了解更多资讯,欢迎前往ChatDZQ官网!
- chatGPT;AI时代;代码
相关文章

扫码在手机访问
随时随地
掌握经营技巧
专业顾问
为您解决经营难题
立即咨询
咨询热线
400-8856-200